SVM也是目前分類效果極好的分類演算法之一,不過我個人使用上沒有那麼習慣,台大的林智仁老師有開發出一款很厲害的SVM工具叫做LIBSVM,在資訊科學領域非常知名,這款工具甚至可以幫你自動調整參數,介面對於非資訊科學背景的使用者也很親切。不過為了操作上的方便性,這邊還是使用sklearn內建的SVM做示範,如果大家有興趣可以自己去玩玩。
從理論上來說,SVM的初衷是希望可以找到一條線完整地把兩個或多個類別的資料點分的最開,如下圖(取自wikipedia),你有兩個類別的資料點,你可以找到多條線去切分他們,如H2或H3,不過直覺上你會發現H3其實比H2理想。探究其中原因,其實是因為兩個類別到線上的垂直距離加總最遠,如此才能夠更乾淨精準的切分兩個類別。因此,你們也可以想像,從數學式子的角度來看,SVM必定是最佳化多個類別到分類線的垂直距離加總最大。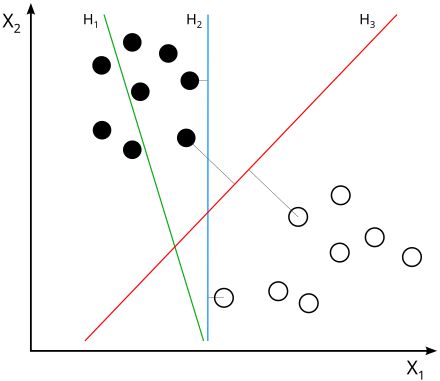
不過以下仍然要解決兩個問題:
如果無法完全切分兩個類別怎麼辦?
這種狀況的視覺化就如同下圖(取自Mr. Opengate.)中的在兩條support vector中間的紅點。而要解決這種error term,其實SVM內部有一個懲罰參數C,可以作為最佳化點到線垂直距離加總的數學式子中的懲罰項。如此一來便能找到,最能夠切分多個類別的線了。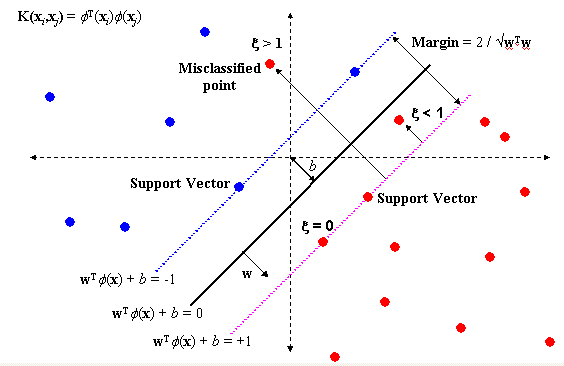
如果類別不是線性可分得怎麼辦?
但是絕大多數的類別並非用直線就可以切分的,因此,在sklearn的設計中,也給你幾個函數式(kernel)選項讓你嘗試: linear, poly, rbf, sigmoi,如下左圖(取自wikipedia)。
kernels =['linear', 'poly', 'rbf', 'sigmoid'] ## 選擇kernel
for name, X, Y in datas:
for k in kernels:
clf = SVC(C=1.0, kernel=k) ## 這邊大家可以調整懲罰項C試試看
clf.fit(X, Y)
y_pred = clf.predict(X)
print('Accuracy', str((Y == y_pred).sum()/ X.shape[0]*100)+"%")
plot_decision_boundary(lambda x: clf.predict(x), X.T, Y)
plt.title(name+'_svm_'+ k +'(' + str((Y == y_pred).sum()/ X.shape[0]*100)+"%)")
plt.savefig(os.path.join('pic', name+'_svm_'+ k))
plt.show()
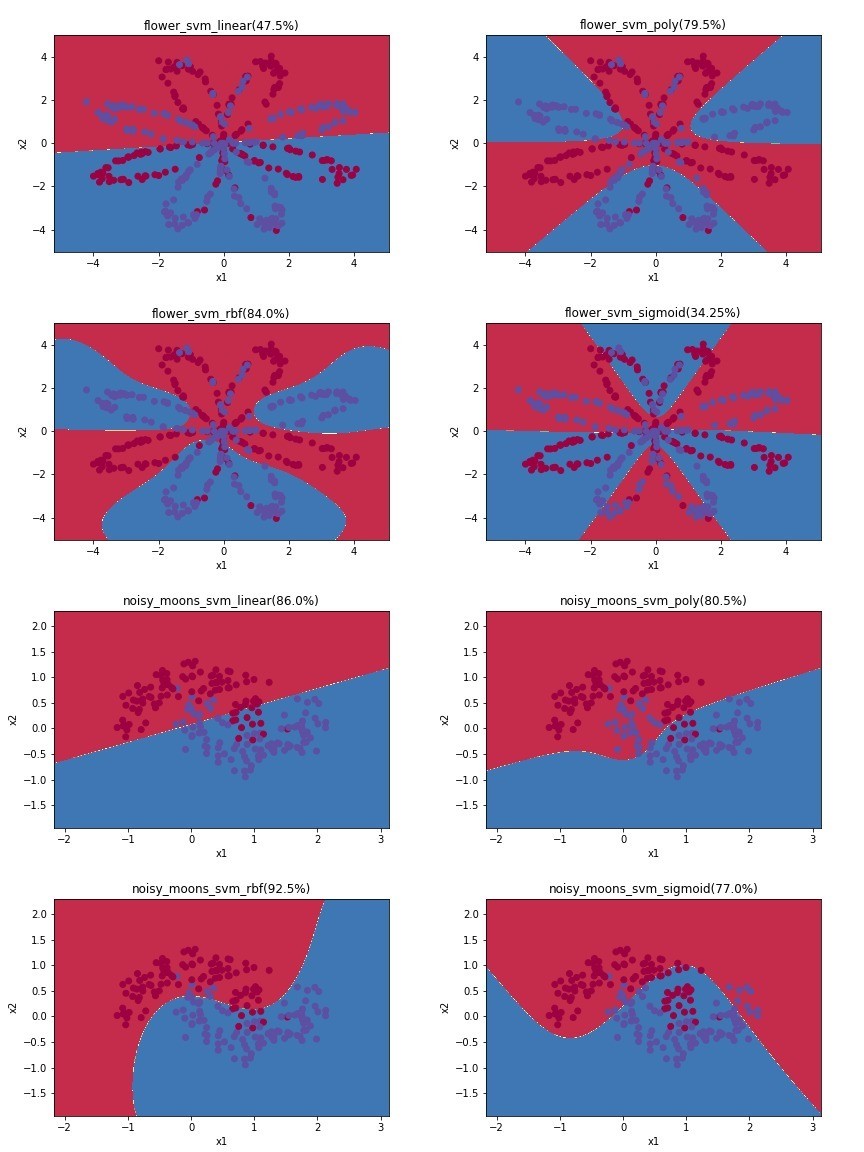
XGBoost(XGB)其實是昨天介紹的decision tree的變形,主要的變形手段有兩個:
以下附上沒有CV的 decision tree, Random Forest, AdaBoosting以及XGBoost的比較,你們會發現因為都是基於決策樹變形做出來的分類法,因此邊界都比較銳利鮮明,也可以看得出來是由很多的if、else組成出來的分類方法。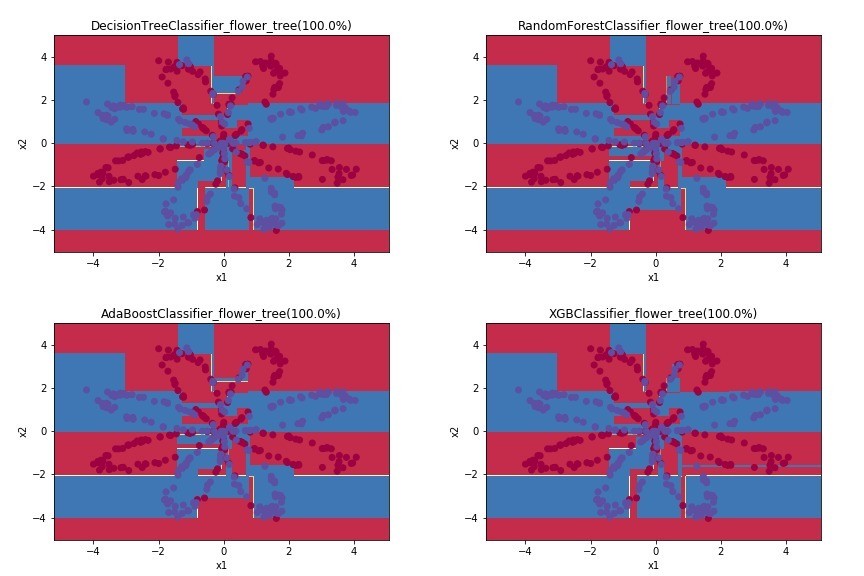
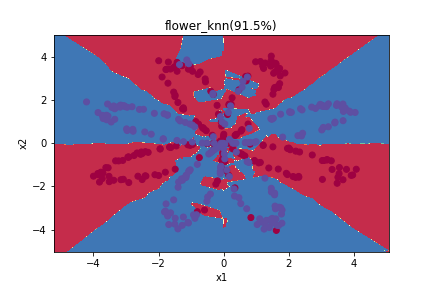
所謂Cross-Validation其實是一門避免overfitting的技巧,所謂overfitting其實就是已經分類分得過於細緻,以至於只有你拿進去訓練的這些資料點,才可以透過這個model預測,如過放進去一個訓練資料中沒有出現過的資料點,就很有可能分類錯誤。其實從昨天的幾個分類方法來看,你們就會發現,SVM的準確率雖然沒那麼高,但是透過函數畫出來的分類方式,跟妳剛開始想像應該要有的方類方式會比較相近,而如果使透過KNN進行分類,他就會針對一些比較小的族群做出例外處理,而這樣的例外處理,就很有可能導致overfitting。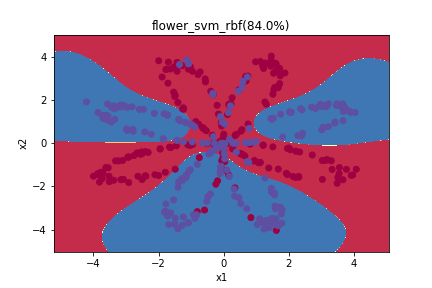
而為了解決這樣的問題,提出cross-validation的方法,主要是透過把整個資料及分成training set以集testing set,在訓練模型時,透過training set進行訓練;在計算accuracy時,透過testing set進行評價。如此以來便能夠增加整個model的推廣能力。
另外,其實昨天文章中的所有演算法與上面的SVM都可以透過Cross-Validation(CV),詳細的做法可以參考這一個notbook,不過使用上個人認為XGBoost在CV的使用上比較方便,所以現在比較常使用的就是透過XGB搭配CV,效果也是非常的好。
由於上面方便視覺化的資料點實在太少,做CV的差異不大,之前示範前處理時使用的Titanic資料集進行示範。
import math
import string
import re
from sklearn.cross_validation import train_test_split
from sklearn.tree import DecisionTreeClassifier ## decision tree
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from xgboost import XGBClassifier
import xgboost
df = pd.read_csv('train.csv')
df = preprocess(df) ## 這個函數請見我的code(在最下面有附上連結)
df.head()
| id | PassengerId | Survived | Pclass | Sex | Age | SibSp | Parch | Ticket | Cabin | Embarked | Has_Cabin | Age_Cat | Fare_log2 | Fare_Cat | Name_Length | Name_With_Special_Char | Family_Size | Title |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | 1 | 22.0 | 1 | 0 | 2 | 0 | 0 | 0 | 1 | 2.857981 | 0 | 23 | 0 | 1 | 1 |
| 1 | 2 | 1 | 1 | 0 | 38.0 | 1 | 0 | 5 | 3 | 2 | 1 | 2 | 6.155492 | 5 | 51 | 1 | 1 | 3 |
| 2 | 3 | 1 | 3 | 0 | 26.0 | 0 | 0 | 7 | 0 | 0 | 0 | 1 | 2.986411 | 0 | 22 | 0 | 0 | 2 |
| 3 | 4 | 1 | 1 | 0 | 35.0 | 1 | 0 | 1 | 3 | 0 | 1 | 2 | 5.730640 | 4 | 44 | 1 | 1 | 3 |
| 4 | 5 | 0 | 3 | 1 | 35.0 | 0 | 0 | 1 | 0 | 0 | 0 | 2 | 3.008989 | 0 | 24 | 0 | 0 | 1 |
X = df[['PassengerId', 'Pclass', 'Sex', 'Age', 'SibSp', 'Parch',
'Ticket', 'Cabin', 'Embarked', 'Has_Cabin', 'Age_Cat', 'Fare_log2',
'Fare_Cat', 'Name_Length', 'Name_With_Special_Char', 'Family_Size',
'Title']].values
Y = df['Survived'].values
X_train, X_valid, Y_train, Y_valid = train_test_split(X, Y, test_size =0.5) ## 一般如果測試資料集超過1000筆就可以了,所以比率不會設這麼高
print(X_train.shape) ## (445, 17)
print(X_valid.shape) ## (446, 17)
print(Y_train.shape) ## (445,)
print(Y_valid.shape) ## (446,)
# 定義函式,輸入分類器,輸出準確率
def get_accuracy(clf):
clf = clf()
clf = clf.fit(X_train, Y_train)
y_pred = clf.predict(X_valid)
return (str(sum(Y_valid == y_pred)/Y_valid.shape[0]))
print('SVM: ', get_accuracy(SVC))
print('DecisionTree: ', get_accuracy(DecisionTreeClassifier))
print('RandomForest: ', get_accuracy(RandomForestClassifier))
print('AdaBoost: ', get_accuracy(AdaBoostClassifier)) ## Boosting的演算法
print('XGB: ', get_accuracy(XGBClassifier))
# SVM: 0.609865470852
# DecisionTree: 0.764573991031
# RandomForest: 0.795964125561
# AdaBoost: 0.784753363229
# XGB: 0.80269058296
# Set our parameters for xgboost
params = {}
params['objective'] = 'binary:logistic'
params['eval_metric'] = 'logloss'
params['eta'] = 0.04
params['max_depth'] = 3
params['learning_rate'] = 0.01
d_train = xgboost.DMatrix(X_train, label=Y_train)
d_valid = xgboost.DMatrix(X_valid, label=Y_valid)
watchlist = [(d_train, 'train'), (d_valid, 'valid')]
bst = xgboost.train(params, d_train, 100, watchlist, early_stopping_rounds=100, verbose_eval=10)
y_pred = bst.predict(xgboost.DMatrix(X_valid))
print("Accuracy: ", str(sum(Y_valid == (y_pred > 0.5))/Y_valid.shape[0]))
## [0] train-logloss:0.687884 valid-logloss:0.6885
## Multiple eval metrics have been passed: 'valid-logloss' will be used for early stopping.
## Will train until valid-logloss hasn't improved in 100 rounds.
## [10] train-logloss:0.640351 valid-logloss:0.646802
## [20] train-logloss:0.600589 valid-logloss:0.612317
## [30] train-logloss:0.566967 valid-logloss:0.583539
## [40] train-logloss:0.538181 valid-logloss:0.559665
## [50] train-logloss:0.513437 valid-logloss:0.53965
## [60] train-logloss:0.492055 valid-logloss:0.522721
## [70] train-logloss:0.473494 valid-logloss:0.508487
## [80] train-logloss:0.457333 valid-logloss:0.496546
## [90] train-logloss:0.443178 valid-logloss:0.48698
## Accuracy: 0.813901345291
整體來說,XGB配上CV的效果是最好的,假設資料集再大一點,這樣的效果會更明顯,而實務上現在在簡單可以用機器學習處理,而無需使用的深度學習的Kaggle比賽中,這樣的訓練方法,也已經漸漸成為主流了。
code在這裡


